
Rerank 指的是重排序模型,在信息检索、自然语言处理等领域有着重要作用。可以有效的提高检索结果准确性、融合多源信息、提升模型性能、挖掘潜在语义关系、平衡召回率和精确率。
一、Xinference 安装

Xinference 是一个性能强大且功能全面的分布式推理框架,特别适用于大语言模型(LLM)、语音识别模型和多模态模型的推理。它支持多种硬件平台,包括 GPU、TPU 以及自定义硬件加速器,能够在不同的硬件上优化推理效率。
开源地址:https://github.com/xorbitsai/xorbits
官方中文文档:https://inference.readthedocs.io/zh-cn
Docker 直接安装:
docker run --name xinference -d -p 9997:9997 -e XINFERENCE_HOME=/data -v </on/your/host>:/data --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0
</on/your/host> 为自定义宿主机数据存储目录,用于保存模型文件等数据。
--gpus all 允许容器使用宿主机上的所有 GPU 资源。这要求宿主机已经安装了 NVIDIA Docker 并且配置正确,以便容器能够访问 GPU。
二、访问 Web UI
安装完成后,访问 web ui 地址:https://localhost:9997
三、安装 Rerank 模型
内置模型列表:https://inference.readthedocs.io/zh-cn/latest/models/builtin/index.html
选择可用的 rerank 模型。
选择 modelscope 下载源,国内下载速度较快:
其他模型也可在该平台安装,我这里还安装了一个 embedding 模型:
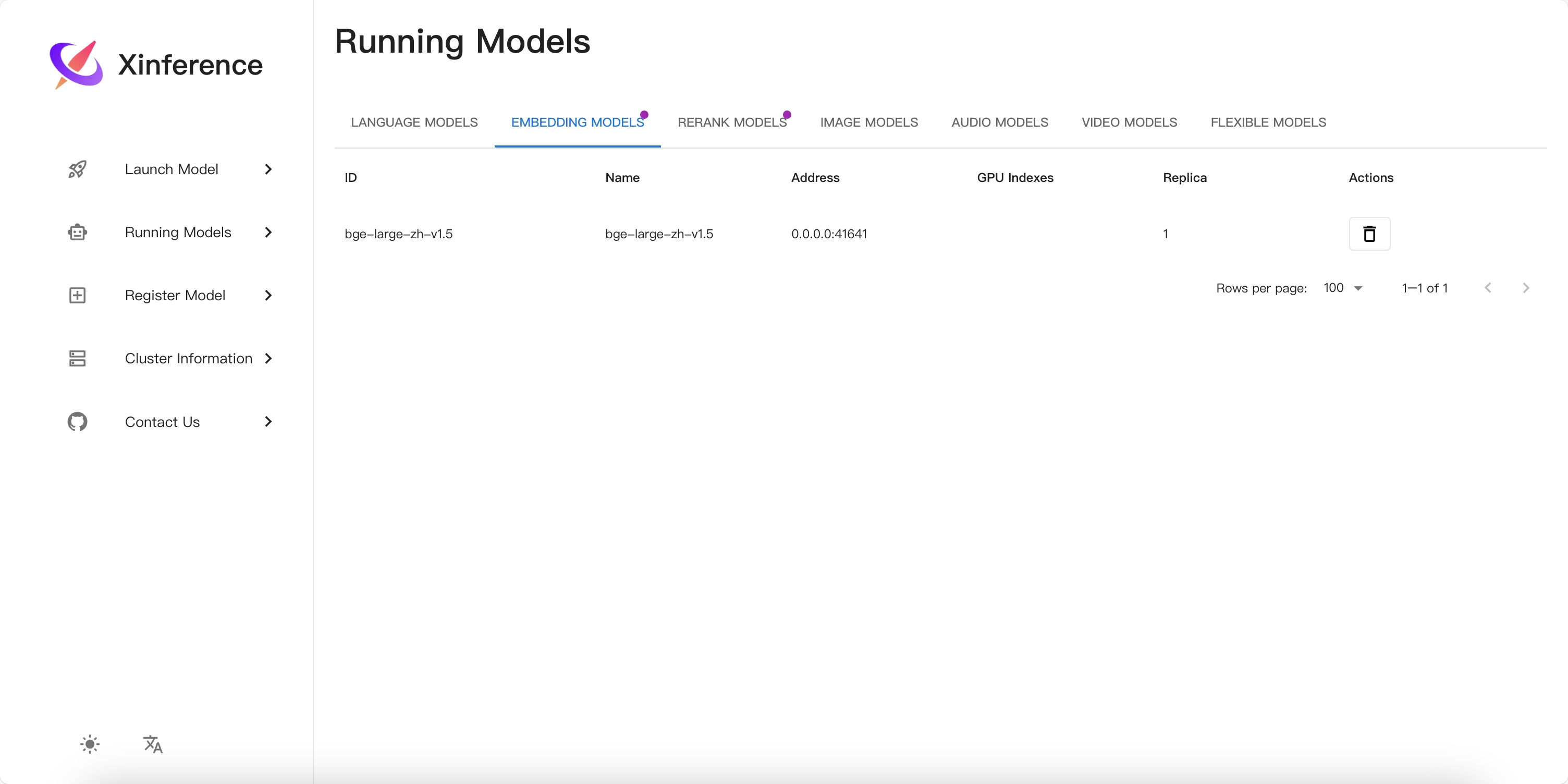
安装完成后可以查看到模型访问端口:
四、在 Dify 中接入模型
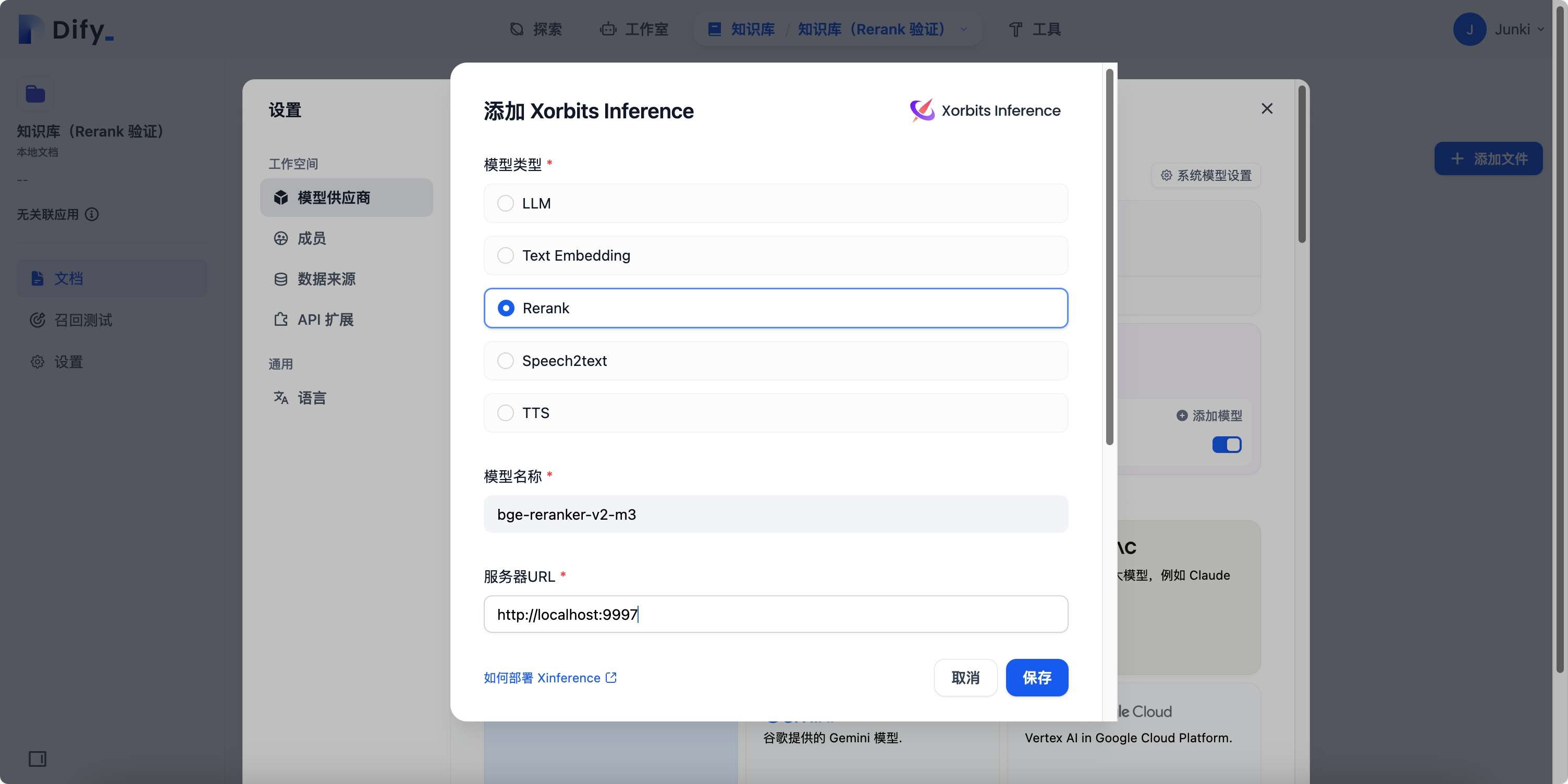
在 Dify 平台右上角 设置 --> 模型供应商 中,选择并接入模型:
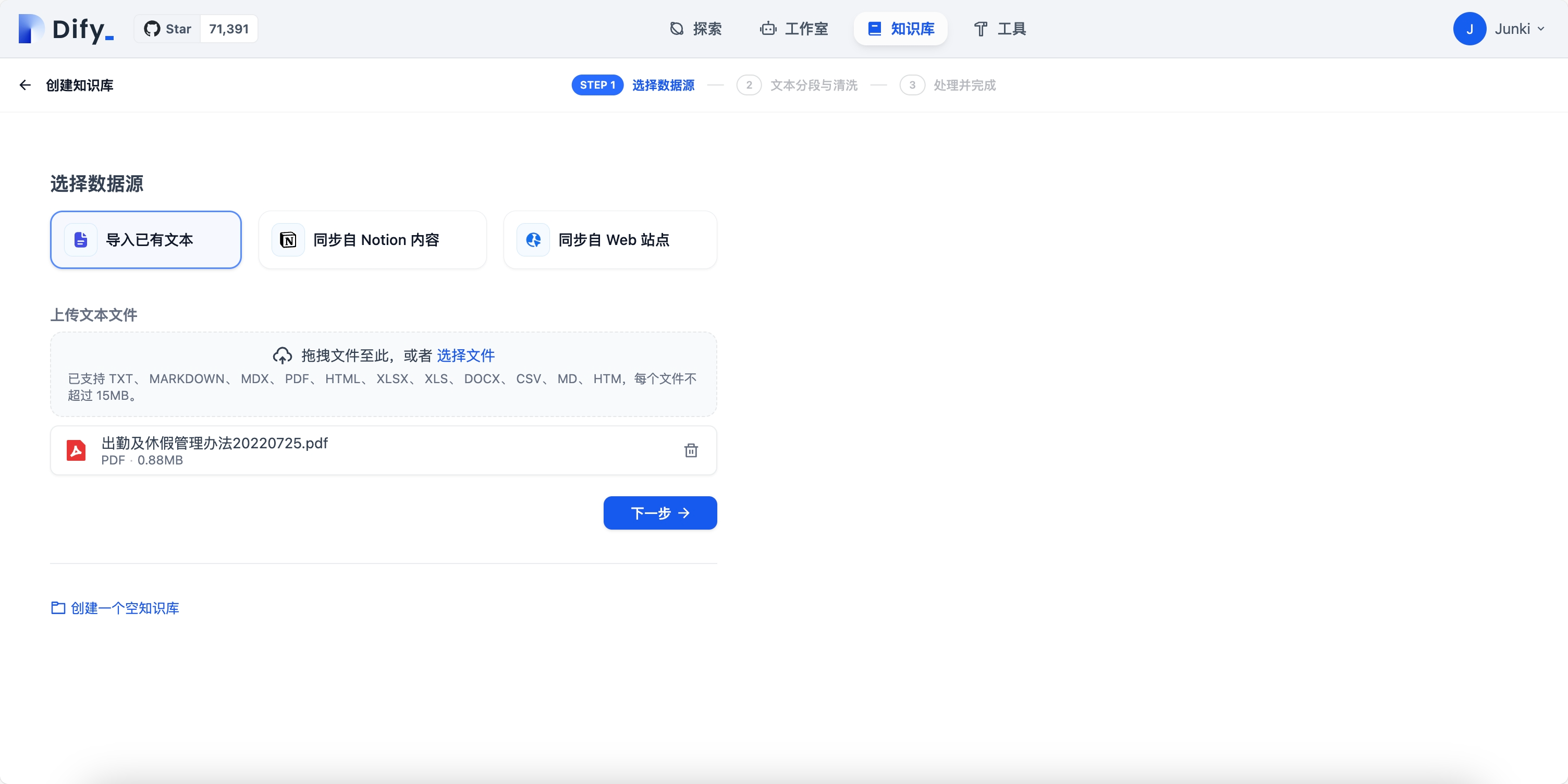
五、创建知识库
在 Dify 中创建一个知识库,并上传文件:
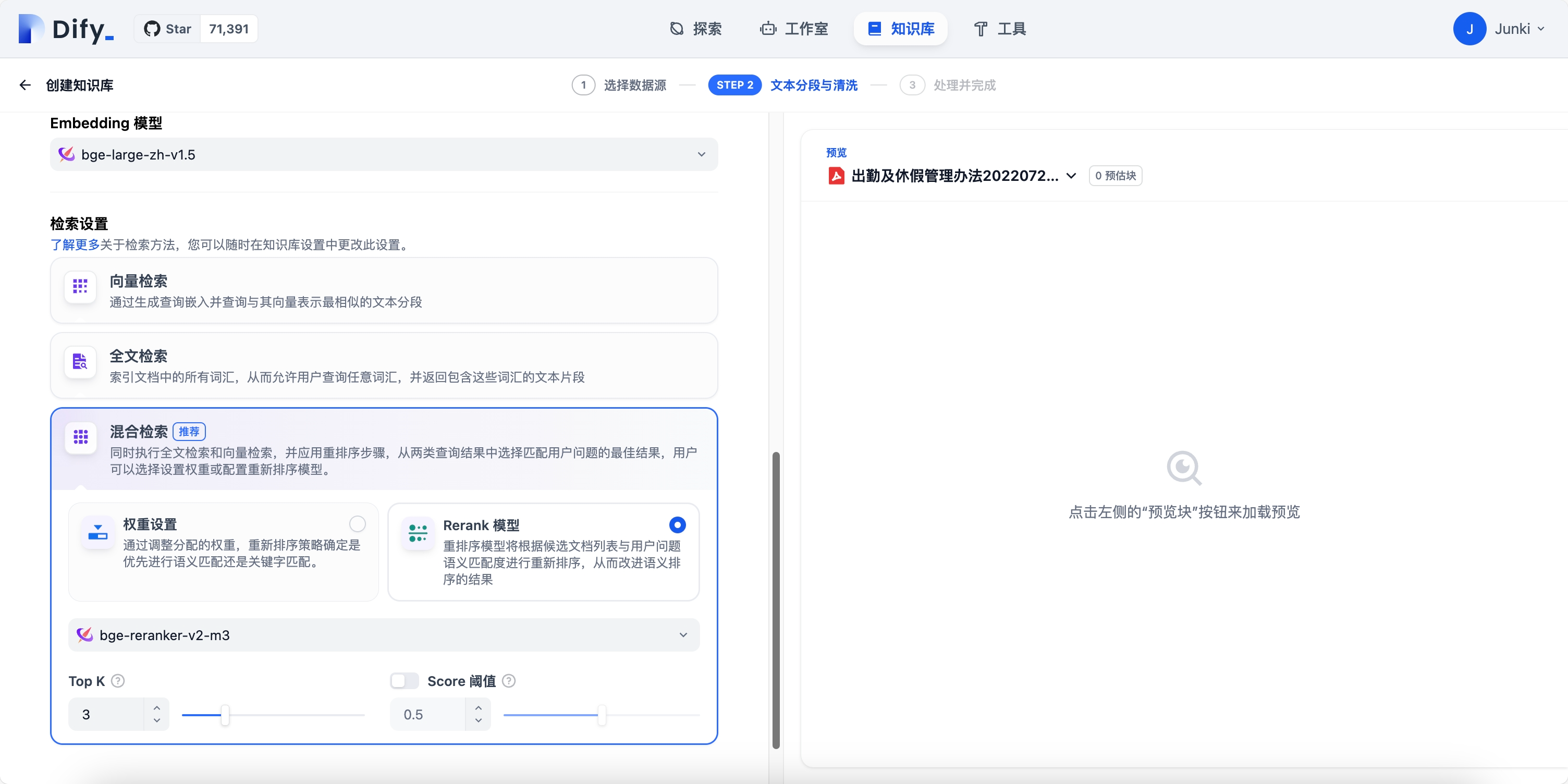
模型选择如下:
六、召回测试
在知识库中,使用召回测试功能,测试知识片段的命中情况:

七、接入大模型对话
接入现有的大模型对话助手,并设置召回规则为 rerank 模型:
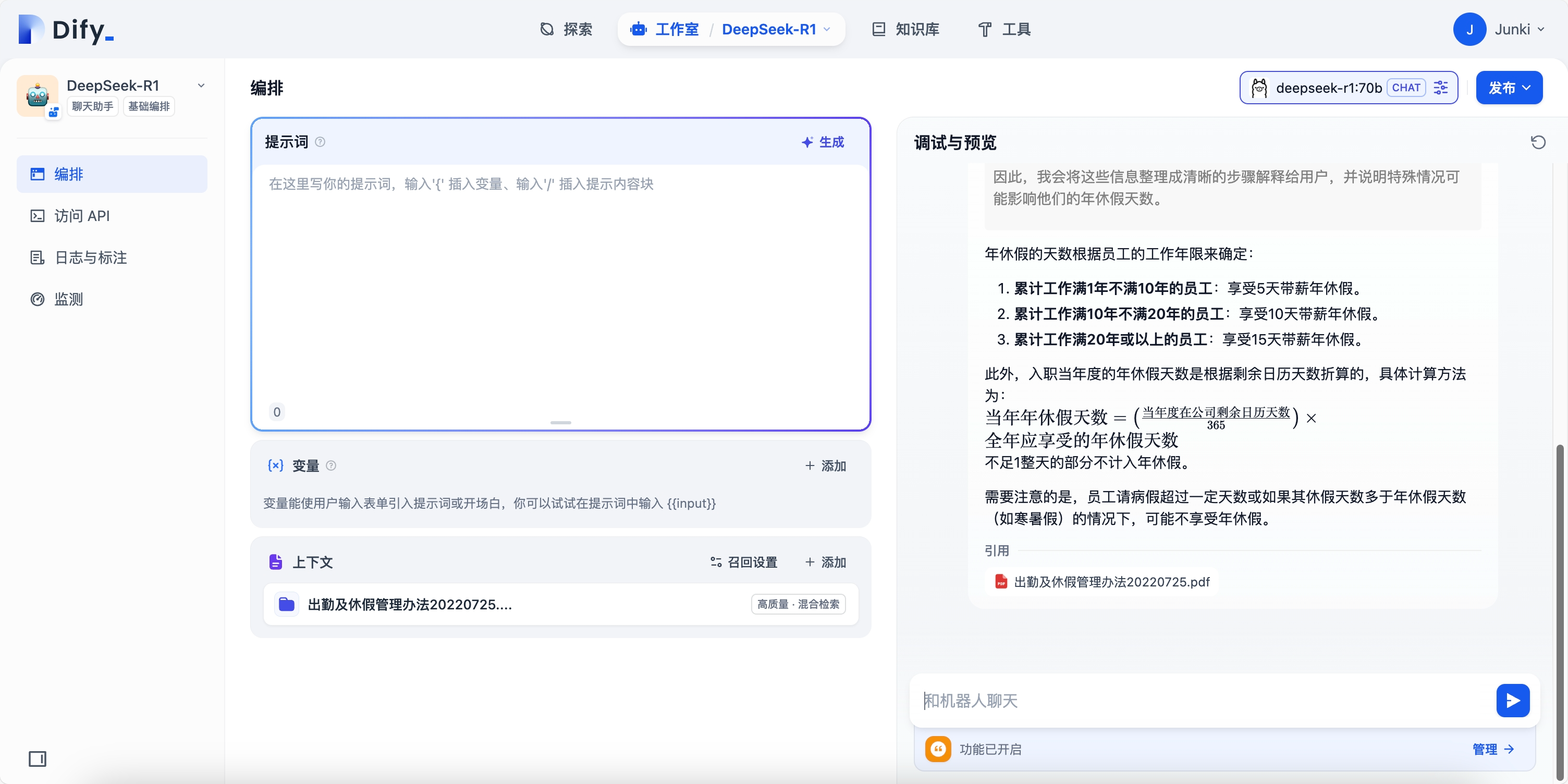
可以看到,正确引用了源文件,并针对召回的知识片段进行了总结回复。